B树
B 树
当数据在磁盘中存储时,磁盘相对于内存读取是非常缓慢的,因此在读取磁盘上的数据时,要尽量减少磁盘IO。
磁盘上的数据是以页为单位存储的,每个磁盘页一般为 4 K。磁盘在某一页上读取数据时,读取 1B 的数据与读取 4K 的数据时间差不了太多,它的时间主要花费在了磁盘寻道与机械运动上。因此,我们需要一种数据结构,它可以把数据分成多个区间,区间越多,查找越快,但是每个节点的区间数又不能超过磁盘的一页,超过一页就会多一次磁盘 IO,降低了效率。
B 树就是这样一棵平衡多路查找树,它的结点所能包含的最大分支数称做阶,一棵 M 阶 B 树具有以下性质:
- 树的根拥有的子结点数在[2, M]之间。
- 除根结点外的所有结点的子结点数在[M/2(向上取整), M]之间。
- 所有叶子结点在相同的深度。
- 有 K 个子结点的父结点拥有 K - 1 个关键字。
下图是一棵 5 阶 B 树:
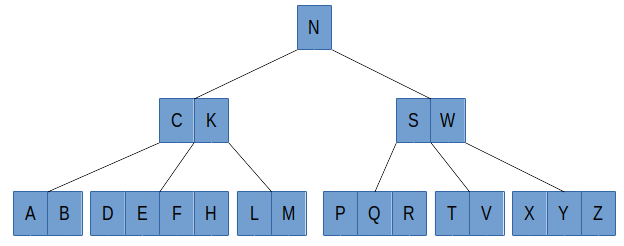
B 树在每次读取下一个结点时会进行磁盘的 IO 操作,这样,B 树的高即为磁盘的读取次数。因此在一个磁盘页可以存储一个结点的情况下,B 树的阶数越大,高越低,意味着进行的磁盘 IO 越少。
B 树的实现
《数据结构与算法分析-C语言描述》 与 《算法导论》 中关于 B 树的定义略有不同,《算法导论》中以最少的孩子数 t (t >= 2) 来定义 B 树,最多的孩子数(即 B 树的阶)为 2t,这里的 B 树的阶必为偶数,且最小的 B 树为 2-3-4 树。《数据结构与算法分析-C语言描述》中最小的 B 树为 2-3 树,并且阶数可以是大于 2 的任何数。这些差异对 B 树影响不会特别大,因为在实际应用中,B 树的阶可能会非常大,且可以固定为偶数。但是在插入和删除操作中有略微的差别,我们在后面实现代码中分别介绍。
这里代码只实现了 B 树的操作,没有包含磁盘操作的代码,实际中B树结点的存储的子结点信息应该是子结点在磁盘中存储位置的信息,每次读取子结点时会从磁盘中读取,这里直接保存了子结点的内存信息,仅供参考。
B 树定义
// 关键字类型
#define BTREE_ELE_TYPE char
// 默认阶数
#define BTREE_DEGREE_DEFAULT (3)
// 错误码类型
#define BTREE_ELEMENT_EXIST (1)
#define BTREE_OK (0)
#define BTREE_FAIL (-1)
#define BTREE_MALLOC_ERR (-2)
#define BTREE_ELEMENT_NOT_EXIST (-3)
// B 树结点定义
typedef struct BTree_Node{
int keyCount; //关键字数
BTREE_ELE_TYPE* keys; //关键字信息
struct BTree_Node** nodes; //子结点
}BTreeNode;
// B 树定义
typedef struct {
int maxDegree; //最大度数,阶数
BTreeNode* root; //根结点
}BTree;
需要实现的接口:
//创建 B 树
BTree* BTreeCreate(int degree);
//销毁 B 树
void BTreeDispose(BTree* tree);
//查找
int BTreeFind(BTree* tree, BTREE_ELE_TYPE value, BTreeNode** node, int* index);
//B 树的插入
int BTreeInsert(BTree* tree, BTREE_ELE_TYPE value);
//B 树的删除
int BTreeDelete(BTree* tree, BTREE_ELE_TYPE value);
实现代码:
//最小度数
static int getMinDegree(int maxDegree)
{
return (maxDegree / 2 + maxDegree % 2);
}
//最大关键字数
static int getMaxKeyCount(int maxDegree)
{
return maxDegree - 1;
}
//最小关键字数
static int getMinKeyCount(int maxDegree)
{
return getMinDegree(maxDegree) - 1;
}
//创建结点
static BTreeNode* BTreeMallocNode(int maxDegree)
{
BTreeNode* node = (BTreeNode*)malloc(sizeof(BTreeNode));
if (node != NULL) {
memset(node, 0, sizeof(BTreeNode));
node->keys = (BTREE_ELE_TYPE*)malloc(sizeof(BTREE_ELE_TYPE) * maxDegree);
if (node->keys == NULL) {
free(node);
return NULL;
}
}
return node;
}
//释放结点
static void BTreeFreeNode(BTreeNode* node)
{
if (node == NULL)
return ;
if (node->keys != NULL) {
free(node->keys);
node->keys = NULL;
}
free(node);
}
//创建 B 树
BTree* BTreeCreate(int degree)
{
if (degree < 3)
return NULL;
BTree* tree = (BTree*) malloc(sizeof(BTree));
if (tree != NULL) {
tree->root = NULL;
tree->maxDegree = degree;
}
return tree;
}
void BTreeDisposeNode(BTreeNode* node)
{
if (node->nodes != NULL) {
for (int i = 0; i <= node->keyCount; i++) {
BTreeDisposeNode(node->nodes[i]);
}
}
BTreeFreeNode(node);
}
void BTreeDispose(BTree* tree)
{
if (tree == NULL)
return ;
if (tree->root != NULL) {
BTreeDisposeNode(tree->root);
tree->root = NULL;
}
free(tree);
}
《算法导论》中需保证阶为偶数,因此创建时做了一个特殊处理:
BTree* BTreeCreate(int degree)
{
if (degree < 3)
return NULL;
//保证阶为偶数,也可以通过定义最小子结点数 t,然后最大子结点数为 2t,这里使用阶来定义
if (degree % 2 == 1)
degree++;
BTree* tree = (BTree*) malloc(sizeof(BTree));
if (tree != NULL) {
tree->root = NULL;
tree->maxDegree = degree;
}
return tree;
}
B 树的查找
B 树的查找与搜索树的查找类似,B 树中的结点把关键字分成了多个区间,要查找的数据与结点的关键字进行比较,如果相等返回查找到的数据,如果不等,根据关键字的大小,去相应区间对应的子结点中查找,直到叶子节点。下图为在一棵五阶 B 树中查找关键字 T 的示例,红色线为查找 T 所经过的路径。
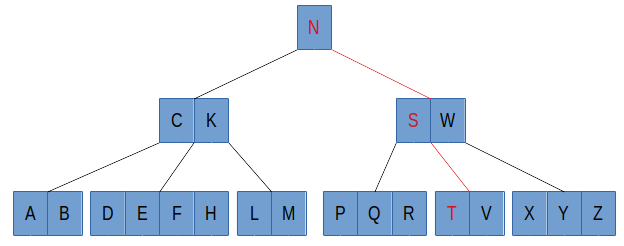
因为 B 树中每个结点的关键字会很多,因此用二分法查找关键字会是比较快速的方法。具体实现:
// 二分法查找关键字
static int BTreeSearchPosDichotomy(BTREE_ELE_TYPE* keys, BTREE_ELE_TYPE value, int begin, int end)
{
if (value > keys[end])
return end+1;
if (begin == end)
return end;
int mid = (begin + end) / 2;
if (value <= keys[mid]) {
return BTreeSearchPosDichotomy(keys, value, begin, mid);
} else {
return BTreeSearchPosDichotomy(keys, value, mid + 1, end);
}
}
// 查找关键字位置
static int BTreeSearchPos(BTreeNode* node, BTREE_ELE_TYPE value)
{
return BTreeSearchPosDichotomy(node->keys, value, 0, node->keyCount - 1);
}
static int BTreeFindNode(BTreeNode* root, BTREE_ELE_TYPE value, BTreeNode** node, int* index)
{
int pos = BTreeSearchPos(root, value);
//找到关键字则返回
if (pos < root->keyCount && root->keys[pos] == value) {
*node = root;
*index = pos;
return BTREE_OK;
}
//未找到则查找对应子结点
if (root->nodes == NULL)
return BTREE_ELEMENT_NOT_EXIST;
BTreeNode* child = root->nodes[pos];
return BTreeFindNode(child, value, node, index);
}
int BTreeFind(BTree* tree, BTREE_ELE_TYPE value, BTreeNode** node, int* index)
{
if (tree == NULL || tree->root == NULL)
return BTREE_FAIL;
return BTreeFindNode(tree->root, value, node, index);
}
B 树的插入
当向 B 树中插入一个值时,会使结点内的关键字增加,就有可能会使结点内的关键字大于最大关键字数 (M - 1),这时,就需要将该结点分列成两个结点放到树中,BTreeSplitNode 是分裂结点的过程实现。下图是一个五阶树结点的分裂过程:
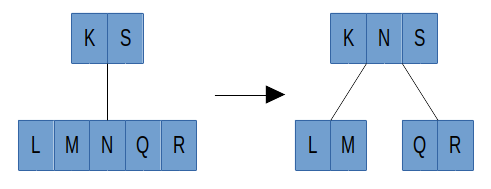
static int BTreeSplitNode(BTreeNode* node, int splitIndex, int maxDegree)
{
BTreeNode* child = node->nodes[splitIndex];
BTreeNode* splitChild = BTreeMallocNode(maxDegree);
if (splitChild == NULL)
return BTREE_MALLOC_ERR;
if (child->nodes != NULL) {
splitChild->nodes = (BTreeNode**)malloc(sizeof(BTreeNode*) * (maxDegree+1));
if (splitChild->nodes == NULL) {
BTreeFreeNode(splitChild);
return BTREE_MALLOC_ERR;
}
}
int t = child->keyCount / 2;
for (int i = 0; i + t + 1 < child->keyCount; i++) {
splitChild->keys[i] = child->keys[i + t + 1];
splitChild->keyCount++;
}
if (child->nodes != NULL) {
for (int i = 0; i + t + 1 < child->keyCount + 1; i++) {
splitChild->nodes[i] = child->nodes[i + t + 1];
}
}
child->keyCount = t;
int i = node->keyCount - 1;
while (i >= splitIndex && i >= 0) {
node->keys[i + 1] = node->keys[i];
node->nodes[i + 2] = node->nodes[i + 1];
i--;
}
node->keys[splitIndex] = child->keys[t];
node->nodes[splitIndex + 1] = splitChild;
node->keyCount++;
return BTREE_OK;
}
第一种实现方式
下面插入过程代码是 《算法导论》中的实现方式,它定义最小结点数为 t,则最小关键字数和为 t - 1,最大结点数 2t,最大关键字数为 2t - 1。这种方式在下行查找插入位置的过程中将可能超最大关键字个数的结点(关键字数目 2t - 1)先分裂成了两个分别具有 t - 1个关键字的结点,之后如果在子结点中插入关键字超限后分裂结点时这两个结点必然不会超限。
static int BTreeInsertNotFull(BTreeNode* root, BTREE_ELE_TYPE value, int maxDegree)
{
int index = BTreeSearchPos(root, value);
if (index < root->keyCount && value == root->keys[index]) {
printf("Element Has Exist!\n");
return BTREE_ELEMENT_EXIST;
}
// leaf node
if (root->nodes == NULL) {
for (int i = root->keyCount - 1; i >= index; i--) {
root->keys[i+1] = root->keys[i];
}
root->keys[index] = value;
root->keyCount++;
return BTREE_OK;
}
int maxKeyCount = getMaxKeyCount(maxDegree);
BTreeNode* child = root->nodes[index];
if (child->keyCount == maxKeyCount)
BTreeSplitNode(root, index, maxDegree);
if (index < root->keyCount && value > root->keys[index])
index = index + 1;
return BTreeInsertNotFull(root->nodes[index], value, maxDegree);
}
int BTreeInsert(BTree* tree, BTREE_ELE_TYPE value)
{
if (tree == NULL || (tree->maxDegree < BTREE_DEGREE_DEFAULT))
return BTREE_FAIL;
if (tree->root == NULL) {
tree->root = BTreeMallocNode(tree->maxDegree);
if (tree->root == NULL)
return BTREE_MALLOC_ERR;
}
int maxKeyCount = getMaxKeyCount(tree->maxDegree);
if (tree->root->keyCount == maxKeyCount) {
BTreeNode* node = BTreeMallocNode(tree->maxDegree);
if (node == NULL)
return BTREE_MALLOC_ERR;
node->nodes = (BTreeNode**) malloc(sizeof(BTreeNode*) * (tree->maxDegree + 1));
if (node->nodes == NULL) {
BTreeFreeNode(node);
return BTREE_MALLOC_ERR;
}
node->keyCount = 0;
node->nodes[0] = tree->root;
tree->root = node;
int ret = BTreeSplitNode(node, 0, tree->maxDegree);
if (ret != BTREE_OK)
return ret;
}
return BTreeInsertNotFull(tree->root, value, tree->maxDegree);
}
第二种实现方式
下面是第二种实现方式,这种方式在每次递归添加完结点后判断结点的关键字数是否超限,如果超限则分裂成两个结点。递归向上,直到根结点。
static int BTreeInsertNode(BTreeNode* root, BTREE_ELE_TYPE value, int maxDegree)
{
int index = BTreeSearchPos(root, value);
if (index < root->keyCount && value == root->keys[index]) {
printf("Element Has Exist!\n");
return BTREE_ELEMENT_EXIST;
}
// leaf node
if (root->nodes == NULL) {
for (int i = root->keyCount - 1; i >= index; i--) {
root->keys[i + 1] = root->keys[i];
}
root->keys[index] = value;
root->keyCount++;
return BTREE_OK;
}
BTreeNode *node = root->nodes[index];
int ret = BTreeInsertNode(node, value, maxDegree);
if (ret == BTREE_ELEMENT_EXIST)
return ret;
int maxKeyCount = getMaxKeyCount(maxDegree);
if (node->keyCount == maxKeyCount + 1)
BTreeSplitNode(root, index, maxDegree);
return BTREE_OK;
}
int BTreeInsert(BTree* tree, BTREE_ELE_TYPE value)
{
if (tree == NULL || (tree->maxDegree < BTREE_DEGREE_DEFAULT))
return BTREE_FAIL;
if (tree->root == NULL) {
tree->root = BTreeMallocNode(tree->maxDegree);
if (tree->root == NULL)
return BTREE_MALLOC_ERR;
}
int maxKeyCount = getMaxKeyCount(tree->maxDegree);
int ret = BTreeInsertNode(tree->root, value, tree->maxDegree);
if (ret == BTREE_ELEMENT_EXIST)
return ret;
if (tree->root->keyCount == maxKeyCount + 1) {
BTreeNode* node = BTreeMallocNode(tree->maxDegree);
if (node == NULL)
return BTREE_MALLOC_ERR;
node->nodes = (BTreeNode**) malloc(sizeof(BTreeNode*) * (tree->maxDegree + 1));
if (node->nodes == NULL) {
BTreeFreeNode(node);
return BTREE_MALLOC_ERR;
}
node->keyCount = 0;
node->nodes[0] = tree->root;
tree->root = node;
int ret = BTreeSplitNode(node, 0, tree->maxDegree);
if (ret != BTREE_OK)
return ret;
}
return BTREE_OK;
}
两种方式都可以实现 B 树的插入,但第一种方式需要在定义 B 树时按偶数的阶定义,即 2t,不可以有奇数阶的 B 树,因为如果是奇数阶,B 树最大子结点数为 2t - 1,最大关键字数为 2t - 2,这样在向下寻找插入位置时,等于最大关键字数 2t - 2 则分裂,分裂过程中因为有一个关键字会上升到父结点,所以两个子结点的关键字数会是 t - 1 和 t - 2,这样就不满足了 B 树的定义(最小关键字数应为 t - 1),所以这种方式必须是偶数阶。
第二种方式可以满足任意阶定义,但会有一些问题,即分裂时子结点会申请新内存,如果申请失败,则分裂失败,这样会造成某一个结点关键字数变为 M,也违背了 B 树的定义。
实际应用中以第一种方式实现会更好一些,因为只要保证 B 树的阶为偶数即可。
B 树的删除
删除关键字后的调整
B 树的删除后可能造成关键字少于最小关键字,所以需要进行调整。调整的方式有几种,如果该结点的兄弟结点有多余关键字,即关键字数大于最小关键字,此时向兄弟结点借关键字,我们将此过程称为 B 树的左旋和右旋,向左兄弟借需要右旋,向右兄弟借需要左旋。如果兄弟结点也没有多余的关键字,则将该结点与兄弟结点合并,变为一个结点。
下图为五阶 B 树的右旋操作,B 树在删除后形成左侧树,在结点 M 处只有一个关键字 M,它的左兄弟有多余关键字,则向它左兄弟借关键字,将它左兄弟的最大关键字上移到父结点,将父结点对应关键字下称到该结点,完成一次右旋。

左旋与右旋类型,将右兄弟的最小关键字上移到父结点,将父结点对应关键字下移到该结点。

当左右结点都没有多余关键字时,将结点与其结点合并,图中为结点与其右结点合并。

static int BTreeLeftRotation(BTreeNode* node, int index)
{
BTreeNode* child = node->nodes[index];
BTreeNode* right = node->nodes[index + 1];
child->keys[child->keyCount] = node->keys[index];
child->keyCount++;
node->keys[index] = right->keys[0];
for (int i = 1; i < right->keyCount; i++)
right->keys[i - 1] = right->keys[i];
if (child->nodes != NULL) {
child->nodes[child->keyCount] = right->nodes[0];
for (int i = 1; i <= right->keyCount; i++)
right->nodes[i - 1] = right->nodes[i];
}
right->keyCount--;
return BTREE_OK;
}
static int BTreeRightRotation(BTreeNode* node, int index)
{
BTreeNode* child = node->nodes[index];
BTreeNode* left = node->nodes[index - 1];
for (int i = child->keyCount; i > 0; i--)
child->keys[i] = child->keys[i - 1];
child->keys[0] = node->keys[index - 1];
if (child->nodes != NULL) {
for (int i = child->keyCount; i >= 0; i--)
child->nodes[i + 1] = child->nodes[i];
child->nodes[0] = left->nodes[left->keyCount];
}
node->keys[index - 1] = left->keys[left->keyCount - 1];
child->keyCount++;
left->keyCount--;
return BTREE_OK;
}
static int BTreeMerge(BTreeNode* node, int index)
{
BTreeNode* left = node->nodes[index];
BTreeNode* right = node->nodes[index + 1];
left->keys[left->keyCount++] = node->keys[index];
int offset = left->keyCount;
for (int i = 0; i < right->keyCount; i++) {
left->keys[i + offset] = right->keys[i];
left->keyCount++;
}
if (left->nodes != NULL) {
for (int i = 0; i < right->keyCount + 1; i++) {
left->nodes[i + offset] = right->nodes[i];
}
}
BTreeFreeNode(right);
for (int i = index + 1; i < node->keyCount; i++) {
node->keys[i - 1] = node->keys[i];
node->nodes[i] = node->nodes[i + 1];
}
node->keyCount--;
return BTREE_OK;
}
要删除的关键字可能出现在叶子结点和内部结点,当出现在叶子结点时,直接删除该关键字,当出现在内部结点时,需要找到该关键字的前驱或后继,用该前驱或后继替换它,会后在相应的子结点中删除对应前驱或后继关键字。查找前驱就是查找左子结点中的最大值,查找后继就是查找右子结点中的最小值,实现代码:
//查找结点最大关键字
int BTreeMaxKey(BTreeNode* node, BTREE_ELE_TYPE* value)
{
if (node == NULL)
return BTREE_FAIL;
if (node->nodes != NULL) {
return BTreeMaxKey(node->nodes[node->keyCount], value);
}
*value = node->keys[node->keyCount - 1];
return BTREE_OK;
}
//查找结点最小关键字
int BTreeMinKey(BTreeNode* node, BTREE_ELE_TYPE* value)
{
if (node == NULL)
return BTREE_FAIL;
if (node->nodes != NULL) {
return BTreeMinKey(node->nodes[0], value);
}
*value = node->keys[0];
return BTREE_OK;
}
删除方法我们也做了两个实现方式,跟前面插入的两种方式对应,第一种方式为在下行寻找结点过程中先对没有多余关键字的结点进行操作,向兄弟结点借关键字或合并,这样执行到删除关键字后可以保证下行的每个结点关键字都不会少于最小关键字数。这种方式同添加时相同,也需要保证 B 树的阶为偶数,否则会出现中间结点合并后超最大关键字数的问题。第二种方式为先查找到关键字进行删除,然后在上溯过程中,判断删除后的结点是否少于最小关键字数,从而做相应的调整。
第一种实现方式
static int BTreeDeleteKey(BTreeNode* node, BTREE_ELE_TYPE value, int maxDegree)
{
int minKeyCount = getMinKeyCount(maxDegree);
int index = BTreeSearchPos(node, value);
if (index < node->keyCount && value == node->keys[index]) {
if (node->nodes == NULL) {
for (int i = index + 1; i < node->keyCount; i++)
node->keys[i - 1] = node->keys[i];
node->keyCount--;
return BTREE_OK;
} else {
BTreeNode* left = node->nodes[index];
BTreeNode* right = node->nodes[index + 1];
if (left->keyCount > minKeyCount) {
BTREE_ELE_TYPE maxKey;
BTreeMaxKey(left, &maxKey);
node->keys[index] = maxKey;
return BTreeDeleteKey(left, maxKey, maxDegree);
} else if (right->keyCount > minKeyCount) {
BTREE_ELE_TYPE minKey;
BTreeMinKey(right, &minKey);
node->keys[index] = minKey;
return BTreeDeleteKey(right, minKey, maxDegree);
} else {
BTreeMerge(node, index);
return BTreeDeleteKey(left, value, maxDegree);
}
}
}
if (node->nodes == NULL)
return BTREE_ELEMENT_NOT_EXIST;
BTreeNode* child = node->nodes[index];
if (child->keyCount > minKeyCount) {
BTreeDeleteKey(child, value, maxDegree);
} else {
BTreeNode* left = NULL;
BTreeNode* right = NULL;
if (index > 0)
left = node->nodes[index - 1];
if (index < node->keyCount)
right = node->nodes[index + 1];
if (left != NULL && left->keyCount > minKeyCount) {
BTreeRightRotation(node, index);
} else if (right != NULL && right->keyCount > minKeyCount) {
BTreeLeftRotation(node, index);
} else {
if (left != NULL) {
BTreeMerge(node, index - 1);
index = index - 1;
}
else
BTreeMerge(node, index);
}
return BTreeDeleteKey(node->nodes[index], value, maxDegree);
}
return BTREE_OK;
}
第二种实现方式
static int BTreeDeleteKey(BTreeNode* node, BTREE_ELE_TYPE value, int maxDegree)
{
int minKeyCount = getMinKeyCount(maxDegree);
int index = BTreeSearchPos(node, value);
BTreeNode* child = NULL;
if (index < node->keyCount && value == node->keys[index]) {
if (node->nodes == NULL) {
for (int i = index + 1; i < node->keyCount; i++)
node->keys[i - 1] = node->keys[i];
node->keyCount--;
return BTREE_OK;
} else {
child = node->nodes[index];
BTREE_ELE_TYPE maxKey;
BTreeMaxKey(child, &maxKey);
node->keys[index] = maxKey;
value = maxKey;
}
} else {
if (node->nodes == NULL)
return BTREE_ELEMENT_NOT_EXIST;
child = node->nodes[index];
}
int ret = BTreeDeleteKey(child, value, maxDegree);
if (child->keyCount < minKeyCount) {
BTreeNode* left = NULL;
BTreeNode* right = NULL;
if (index > 0)
left = node->nodes[index - 1];
if (index < node->keyCount)
right = node->nodes[index + 1];
if (left != NULL && left->keyCount > minKeyCount)
BTreeRightRotation(node, index);
else if (right != NULL && right->keyCount > minKeyCount)
BTreeLeftRotation(node, index);
else {
if (left != NULL)
BTreeMerge(node, index - 1);
else
BTreeMerge(node, index);
}
}
return BTREE_OK;
}
从树中删除后关键字后的调整可能会面临树高降低,需要在树中做相应的调整。
int BTreeDelete(BTree* tree, BTREE_ELE_TYPE value)
{
if (tree == NULL || tree->root == NULL)
return BTREE_FAIL;
int ret = BTreeDeleteKey(tree->root, value, tree->maxDegree);
if (tree->root->keyCount == 0) {
BTreeNode* node = tree->root;
if (node->nodes != NULL)
tree->root = node->nodes[0];
else
tree->root = NULL;
BTreeFreeNode(node);
}
return ret;
}
测试代码
typedef void (*BTreeOperateFunc)(BTreeNode* node);
void printBTreeNode(BTreeNode* node)
{
printf("[");
for (int i = 0; i < node->keyCount; i++) {
printf("%c ", node->keys[i]);
}
printf("] ");
}
//使用层次遍历打印该 B 树
void traversalBTreeInLevelOrder(BTree* tree, BTreeOperateFunc func)
{
if (tree == NULL || tree->root == NULL)
return ;
ttQueue* queue = createQueue(0);
if (queue == NULL)
return ;
enqueue(queue, tree->root);
int levelCount = queueSize(queue);
while (!queueEmpty(queue)) {
BTreeNode* node = (BTreeNode*)dequeue(queue);
if (node != NULL) {
if (node->nodes != NULL) {
for (int i = 0; i <= node->keyCount; i++) {
enqueue(queue, node->nodes[i]);
}
}
if (func != NULL)
func(node);
if (--levelCount == 0) {
printf("\n");
levelCount = queueSize(queue);
} else {
printf("\t");
}
}
}
disposeQueue(queue);
}
void BTreeTest()
{
BTree* tree = BTreeCreate(5);
if (tree == NULL) {
printf("BTree create error\n");
return ;
}
char value[] = {
'F', 'S', 'Q', 'K', 'C', 'L', 'H', 'T', 'V', 'W', 'M',
'R', 'N', 'P', 'A', 'B', 'X', 'Y', 'D', 'Z', 'E'
};
int length = sizeof(value) / sizeof(char);
for (int i = 0; i < length; i++) {
int ret = BTreeInsert(tree, value[i]);
printf("\n\nInsert %c:\n", value[i]);
traversalBTreeInLevelOrder(tree, printBTreeNode);
}
printf("\n\n");
printf("Now Delete\n");
for (int i = 0; i < length; i++) {
int ret = BTreeDelete(tree, value[i]);
printf("\nDelete %c:\n", value[i]);
traversalBTreeInLevelOrder(tree, printBTreeNode);
}
BTreeDispose(tree);
}
int main(int argc, char* argv[])
{
BTreeTest();
return 0;
}
参考:
<数据结构与算法分析-C语言描述> P4 <算法导论>第三版 P18- 版权声明:
